使用 Mutex,不管是读还是写,我们都通过 Mutex 来保证只有一个 goroutine 访问共享资源,这在某些情况下有点“浪费”,例如读多写少的情况。
在使用读写锁的情况下,某个读操作的 goroutine 持有了锁,在这种情况下,其它读操作的 goroutine 就不必一直傻傻地等待了,而是可以并发地访问共享变量,这样我们就可以将串行的读变成并行读,提高读操作的性能。当写操作的 goroutine 持有锁的时候,它就是一个排外锁,其它的写操作和读操作的 goroutine,需要阻塞等待持有这个锁的 goroutine 释放锁。
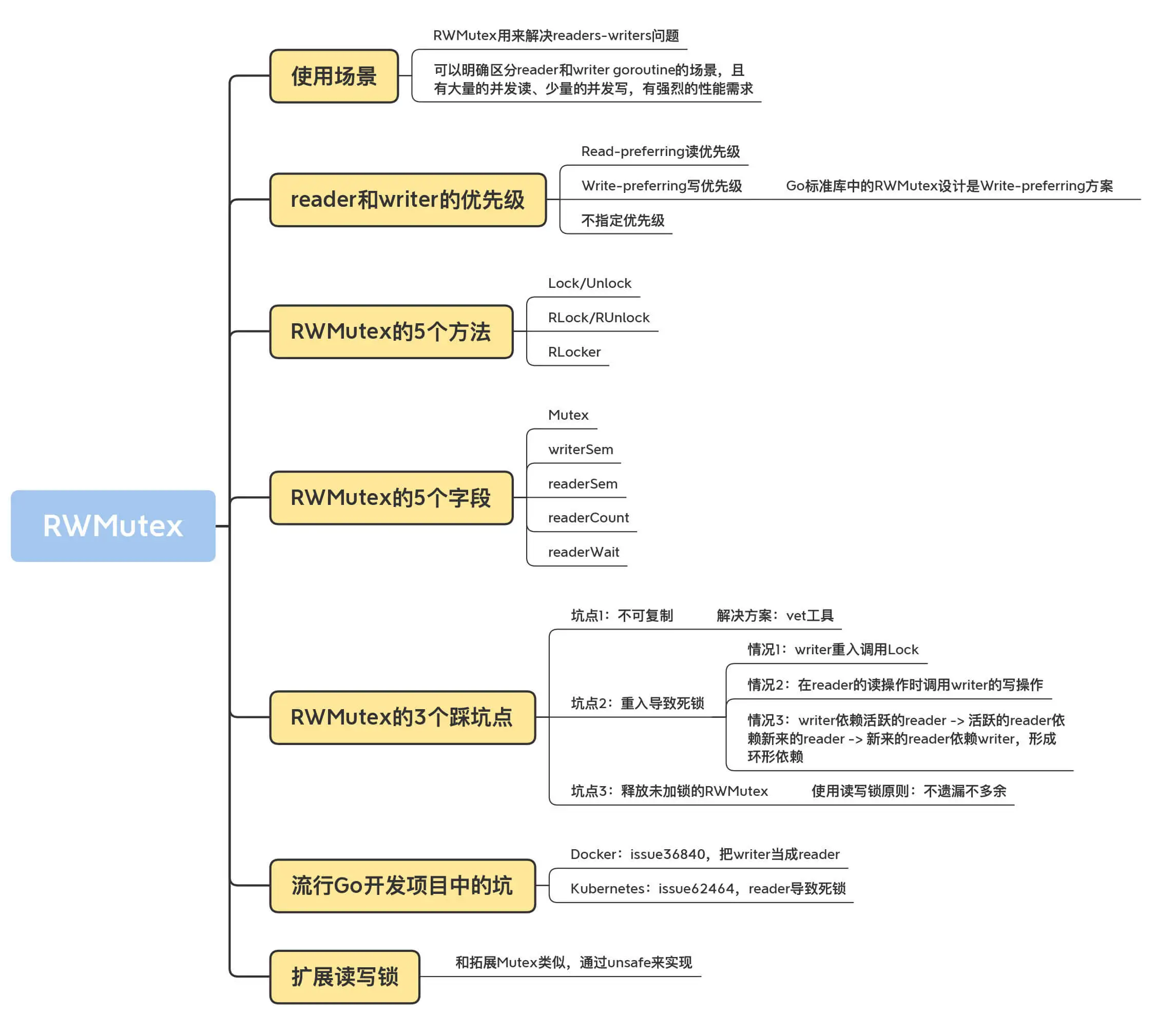
RWMutex
RWMutex 是一个 reader/writer 互斥锁。RWMutex 在某一时刻只能由任意数量的 reader 持有,或者是只被单个的 writer 持有。
RWMutex 的方法如下:
- Lock/Unlock:写操作时调用的方法。如果锁已经被 reader 或者 writer 持有,那么,Lock 方法会一直阻塞,直到能获取到锁;Unlock 则是配对的释放锁的方法。
- RLock/RUnlock:读操作时调用的方法。如果锁已经被 writer 持有的话,RLock 方法会一直阻塞,直到能获取到锁,否则就直接返回;而 RUnlock 是 reader 释放锁的方法。
- RLocker:这个方法的作用是为读操作返回一个 Locker 接口的对象。它的 Lock 方法会调用 RWMutex 的 RLock 方法,它的 Unlock 方法会调用 RWMutex 的 RUnlock 方法。
场景举例:使用 10 个 goroutine 进行读操作,每读取一次,sleep 1 毫秒,同时,还有一个 gorotine 进行写操作,每一秒写一次,这是一个 1 writer-n reader 的读写场景。
1 |
|
上述代码中在读取 count 值的时候,可以并发进行。所以和 Mutex 相比,效率上有很大的提升。
实现原理
Go 标准库中的 RWMutex 设计是Write-preferring 方案。一个正在阻塞的 Lock 调用会排除新的 reader 请求到锁。但是老的 reader 并不受影响。
- Read-preferring:读优先的设计可以提供很高的并发性,但是,在竞争激烈的情况下可能会导致写饥饿。这是因为,如果有大量的读,这种设计会导致只有所有的读都释放了锁之后,写才可能获取到锁。
- Write-preferring:写优先的设计意味着,如果已经有一个 writer 在等待请求锁的话,它会阻止新来的请求锁的 reader 获取到锁,所以优先保障 writer。当然,如果有一些 reader 已经请求了锁的话,新请求的 writer 也会等待已经存在的 reader 都释放锁之后才能获取。所以,写优先级设计中的优先权是针对新来的请求而言的。这种设计主要避免了 writer 的饥饿问题。
- 不指定优先级:这种设计比较简单,不区分 reader 和 writer 优先级,某些场景下这种不指定优先级的设计反而更有效,因为第一类优先级会导致写饥饿,第二类优先级可能会导致读饥饿,这种不指定优先级的访问不再区分读写,大家都是同一个优先级,解决了饥饿的问题。
RWMutex 包含一个 Mutex,以及四个辅助字段 writerSem、readerSem、readerCount 和 readerWait:
1 |
|
RLock/RUnlock 的实现
1 |
|
Lock
1 |
|
func AddInt32(addr *int32, delta int32) (new int32)
addr是要修改的int32类型变量的指针,delta是要增加或减少的值。调用该函数后,该变量的值会增加或减少delta,并返回新的值。值得注意的是这里的 addr 的值已经改变后了的,然后在返回。所以上述代码中 rw.readerCount 变为了一个负数。
Unlock
当一个 writer 释放锁的时候,它会再次反转 readerCount 字段。可以肯定的是,因为当前锁由 writer 持有,所以,readerCount 字段是反转过的,并且减去了 rwmutexMaxReaders 这个常数,变成了负数。所以,这里的反转方法就是给它增加 rwmutexMaxReaders 这个常数值。
既然 writer 要释放锁了,那么就需要唤醒之后新来的 reader,不必再阻塞它们了
在 RWMutex 的 Unlock 返回之前,需要把内部的互斥锁释放。释放完毕后,其他的 writer 才可以继续竞争这把锁。
1 |
|
在 Lock 方法中,是先获取内部互斥锁,才会修改的其他字段;而在 Unlock 方法中,是先修改的其他字段,才会释放内部互斥锁,这样才能保证字段的修改也受到互斥锁的保护。
使用注意事项
不可复制
RWMutex 是由一个互斥锁和四个辅助字段组成的。我们很容易想到,互斥锁是不可复制的,再加上四个有状态的字段,RWMutex 就更加不能复制使用了。不能复制的原因和互斥锁一样。一旦读写锁被使用,它的字段就会记录它当前的一些状态。这个时候你去复制这把锁,就会把它的状态也给复制过来。但是,原来的锁在释放的时候,并不会修改你复制出来的这个读写锁,这就会导致复制出来的读写锁的状态不对,可能永远无法释放锁。
不可重入使用
常见的重入场景
1 |
|
reader 读操作时调用 writer 的写操作
有活跃 reader 的时候,writer 会等待,如果我们在 reader 的读操作时调用 writer 的写操作(它会调用 Lock 方法),那么,这个 reader 和 writer 就会形成互相依赖的死锁状态。Reader 想等待 writer 完成后再释放锁,而 writer 需要这个 reader 释放锁之后,才能不阻塞地继续执行。这是一个读写锁常见的死锁场景。
更加隐蔽的场景
当一个 writer 请求锁的时候,如果已经有一些活跃的 reader,它会等待这些活跃的 reader 完成,才有可能获取到锁,但是,如果之后活跃的 reader 再依赖新的 reader 的话,这些新的 reader 就会等待 writer 释放锁之后才能继续执行,这就形成了一个环形依赖: writer 依赖活跃的 reader -> 活跃的 reader 依赖新来的 reader -> 新来的 reader 依赖 writer。
释放未加锁的 RWMutex
和互斥锁一样,Lock 和 Unlock 的调用总是成对出现的,RLock 和 RUnlock 的调用也必须成对出现。Lock 和 RLock 多余的调用会导致锁没有被释放,可能会出现死锁,而 Unlock 和 RUnlock 多余的调用会导致 panic
RWMUtex 总结